Docenthandleiding

Voor po-bovenbouw tot hbo — zonder installatie of account.

Inhoud
- Inleiding & uitgangspunten04
- Van digitale geletterdheid naar generatieve AI05
- DigComp 3.0 & de kerndoelen06
- Welke raamwerken liggen eronder?07
- De praatplaat08
- Groene zone · presentatie & debat09
- Blauwe zone · AI bouwen15
- Gele zone · onbewust gebruik22
- Paarse zone · bewust gebruik28
- Technische handleiding38
- Didactische handvatten46
- Pedagogische memo’s48
- Lexicon & bronnen49
Inleiding
Dit is een beta-versie. In februari wordt de eindversie opgeleverd. Feedback geven? Klik hier.
De AIpraatplaat is ontwikkeld binnen een Teaching Fellow-programma van het Nationaal Regieorgaan Onderwijsonderzoek (NRO). Het project ontstond vanuit de behoefte op de Hanze Pedagogische Academie om AI-geletterdheid steviger te verankeren in de lerarenopleiding en om concrete handvatten voor docenten te bieden. Die behoefte sluit aan bij de sectordoelen van Npuls, dat ernaar streeft dat lerenden en onderwijsprofessionals in het vervolgonderwijs generatieve AI veilig en waardevol kunnen gebruiken (Npuls, n.d.).
De praatplaat is bewust contextonafhankelijk opgezet. Casuïstiek en verdieping brengt de docent zelf aan, afgestemd op de eigen groep en context. Dat maakt het instrument breed inzetbaar: in het hbo — ook buiten de lerarenopleiding — maar evengoed in het mbo, het voortgezet onderwijs en (met goede ondersteuning van de leerkracht) de bovenbouw van het primair onderwijs.
De praatplaat brengt het gesprek over generatieve AI op gang tussen docenten en leerlingen. Het is nadrukkelijk een praatplaat, geen infographic: het legt niet meteen alles uit, maar roept vragen op en legt perspectieven naast elkaar. Je hoeft de plaat dan ook niet volledig te kunnen uitleggen of zelfs te begrijpen — je gebruikt het om samen met je doelgroep te kijken, te vergelijken en te bespreken.
De focus ligt daarbij op de AI-geletterdheid die nodig is om generatieve AI te begrijpen, te gebruiken en kritisch te duiden — niet op een volledig overzicht van alle vormen van kunstmatige intelligentie.
Vijf principes sturen het ontwerp van de plaat én de manier waarop je die inzet:
Docent als senior co-learner
De docent houdt de regie, maar hoeft niet alle antwoorden paraat te hebben. Samen kijken, vragen stellen en onderzoeken wat AI-geletterdheid in concrete situaties betekent.
Geen antropomorfe kenmerken
AI-systemen zijn het resultaat van menselijke keuzes over data, ontwerp, doel en inzet — en kennen geen begrip of empathie. De plaat toont daarom mensen en systemen, geen pratende robots.
Bewustwording zonder oordeel
De plaat schrijft niet voor wat goed of fout is. Samen leren kijken — wat zie je, wat roept het op? — levert een rijker gesprek op dan sturen vanuit een sterk normatief kader.
Dynamisch, niet lineair
Je hoeft niet bij scène 1 te beginnen. Kies een scène die past bij je groep of les, en kijk waar het gesprek je brengt.
Didactisch vereenvoudigd
Veel scènes zijn bewust versimpeld. Soms lijkt een proces daardoor eenvoudiger dan het is; in de „Let op”-kaders worden nuances aangebracht.
Van digitale geletterdheid naar generatieve AI
Het gesprek dat deze plaat op gang brengt begint eigenlijk bij digitale geletterdheid. AI-geletterdheid is daarin onlosmakelijk verweven.
Digitale geletterdheid is het geheel van kennis, vaardigheden en houdingen waarmee je kunt meedoen in een gedigitaliseerde wereld. In het Nederlandse funderend onderwijs krijgt dat vorm in het leergebied digitale geletterdheid, met drie domeinen: praktische kennis en vaardigheden, ontwerpen en maken en de gedigitaliseerde wereld (SLO, 2025).
De WRR bestempelde AI als een systeemtechnologie die de samenleving fundamenteel verandert (WRR, 2021) — en zo gedraagt AI zich ook in het curriculum: wie het over AI heeft, heeft het vanzelf ook over informatievaardigheden, mediawijsheid, data, veiligheid en de relatie tussen mens en machine. AI-geletterdheid is dan ook geen aparte geletterdheid náást de digitale, maar een verdieping erbinnen. Je kunt ze niet los van elkaar zien.
Voor het ontwerp van deze praatplaat is uitgebreid literatuuronderzoek gedaan, maar voor deze handleiding beperken we ons tot de meest toonaangevende kaders. Twee begrippen verdienen daarbij vooraf verheldering:
Generatieve AI
“computertechnieken die op basis van trainingsgegevens schijnbaar nieuwe, ‘betekenisvolle’ inhoud genereren zoals tekst, afbeeldingen of audio.”
Feuerriegel et al. (2024), geciteerd in Renkema et al. (2025)AI-geletterdheid
“AI-geletterdheid verwijst naar het samenspel van kennis, vaardigheden en attituden, waarbij ethisch bewustzijn de basis vormt voor het kritisch, verantwoordelijk en effectief omgaan met AI-systemen.”
Renkema et al. (2025) — AI-GO raamwerkOp de volgende twee pagina's gaan we dieper in op de bovenstaande concepten en onderliggende raamwerken.
DigComp 3.0 & de kerndoelen
Twee onderleggers verbinden de plaat met het bredere leergebied digitale geletterdheid: het Europese referentiekader DigComp 3.0 en de Nederlandse kerndoelen.

DigComp 3.0
De vijfde editie van het Europese referentiekader voor digitale competentie: vijf gebieden, 21 competenties. AI-competentie is er níet als apart domein aan toegevoegd, maar systematisch en transversaal verweven: AI komt — expliciet of impliciet — in alle 21 competenties terug. DigComp ziet AI als één digitale technologie te midden van andere; AI-competentie bouwt voort op, en is vervlochten met, de rest van digitale competentie.
Bekijk DigComp 3.0 →
Kerndoelen digitale geletterdheid
De definitieve conceptkerndoelen (po en onderbouw vo) ordenen het leergebied in drie domeinen. AI krijgt hier een eigen subdoel — „De leerling verkent AI” (po 22D / vo 21D) — maar raakt elk gebied van digitale geletterdheid: het belang van data voor de werking van AI, AI in digitale media en zoekhulpmiddelen, veiligheid en privacy, en de relatie mens-machine, met ethiek als nadrukkelijk thema.
Bekijk de kerndoelen →Door dit instrument te gebruiken behandel je dus niet alleen generatieve AI — je werkt aan digitale geletterdheid in de volle breedte: informatievaardigheden, mediawijsheid, data, veiligheid en burgerschap in een gedigitaliseerde wereld.
In de praktijk: bespreek je met de plaat hoe een model getraind wordt (scène 3–12), dan werk je aan praktische kennis en vaardigheden; gaat het over deepfakes, privacy en het publieke debat, dan zit je middenin de gedigitaliseerde wereld. De AI-specifieke raamwerken die de scènes vormgaven, vind je op de volgende pagina.
Raamwerken AI-geletterdheid
Naast deze brede onderleggers is de AIpraatplaat gebouwd op AI-specifieke, nationaal en internationaal erkende kaders. Drie raamwerken gaven de scènes vorm; ze richten zich vooral op de AI-geletterdheid van leerlingen in het vo en studenten in het vervolgonderwijs. Daarnaast bestaan er docentspecifieke kaders — het UNESCO-raamwerk voor docenten. Een recenter raamwerk AI-geletterdheid voor Docenten (Last, Naberink & Mutsaarts, 2026) valt ook goed te koppelen aan deze praatplaat.
Voor leerlingen & studenten
AI-GO-raamwerk
Opgebouwd rond vier componenten: kennis over AI, vaardigheden met AI, attituden over AI en ethiek met AI — een dynamisch samenspel, met ethisch bewustzijn steevast als fundament. Geen gelaagde progressieniveaus, maar clusters met toetsbare indicatoren.
Bekijk het AI-GO-raamwerk →
AILit Framework
Ordent AI-geletterdheid langs vier domeinen: AI gebruiken, ermee creëren, AI beheren of aansturen en AI ontwerpen. Daaronder hangen 22 competenties — telkens een leerverwachting van kennis, vaardigheden en attituden — met ethische principes als onderligger.
Bekijk het AILit Framework →
AI Competency Framework for Students
Benadert studenten als actieve, verantwoordelijke burgers. Twaalf competenties over vier dimensies — een mensgerichte mindset, de ethiek van AI, AI-technieken en -toepassingen, en AI-systeemontwerp — lopen over drie oplopende niveaus: begrijpen, toepassen en creëren.
Bekijk het UNESCO-raamwerk →
AI Competency Framework for Teachers
Benadrukt een mensgerichte benadering van AI en verdeelt de competenties over vijf aspecten: een mensgerichte mindset, ethiek van AI, AI-fundamenten en toepassingen, AI-pedagogiek, en AI voor professionele ontwikkeling.
Bekijk het UNESCO-raamwerk →Al deze raamwerken zijn waardevol, maar in de praktijk ook complex: kennis, vaardigheden, houding en ethiek lopen dwars door elkaar. De praatplaat maakt die samenhang concreet en bespreekbaar.
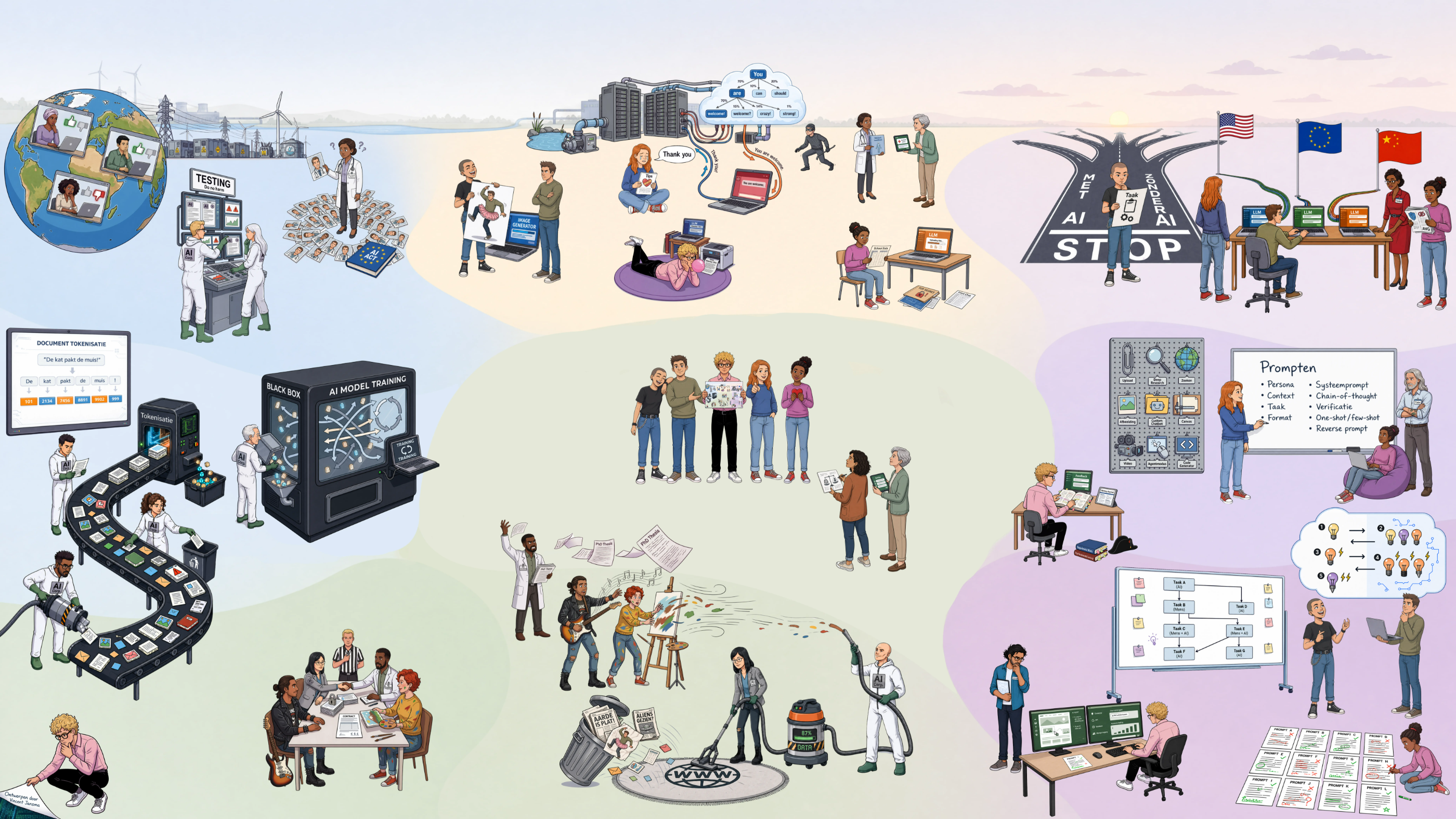
De praatplaat
De achtergrondkleuren clusteren de scènes. Een logische ingang ligt in het midden — de presentatie op het groene vlak — van waaruit het gesprek alle kanten op kan gaan.
Groen · presentatie & debat
De centrale presentatie en het maatschappelijke debat: eigenaarschap, transparantie, auteursrecht en publieke waarden.
Blauw · AI bouwen
Het ontwerpen van AI-systemen: dataverzameling, filteren, tokenisatie, trainen, testen en bijsturen.
Geel · onbewust gebruik
De valkuilen: gemakzucht, antropomorfisme, hallucinaties, deepfakes en privacyrisico's.
Paars · bewust gebruik
Van het STOP-moment naar technische en cognitieve vaardigheden: kiezen, prompten, controleren en aansturen.
Op de volgende pagina's loop je de plaat scène voor scène door — per zone gebundeld, te beginnen in het midden bij de groene zone.
De presentatie
Deze centrale afbeelding is de ingang van de praatplaat. Vijf studenten houden samen een praatplaat vast — en in díe plaat duiken ze opnieuw op, met weer een praatplaat. Zo ontstaat een droste-effect: een beeld dat zichzelf herhaalt.
Het droste-effect verwijst naar een belangrijk houdingsaspect: transparantie over je eigen AI-gebruik. De studenten laten zien dat ook deze plaat met behulp van AI tot stand kwam. Ze verbergen dat niet, maar maken het bespreekbaar. De vijf studenten overkomen hier hun eventuele AI-schaamte. Verantwoord omgaan met AI betekent niet dat je gebruik moet verzwijgen, maar dat je kunt uitleggen waarom en hóe je AI op verantwoorde wijze hebt ingezet.

- Wat laten de studenten hier eigenlijk zien aan het publiek?
- Waarom kan het belangrijk zijn om open te zijn over je AI-gebruik?
- Wie ervaart wel eens AI-schaamte?
- In hoeverre weerhoudt dat je om open te zijn over je AI-gebruik — en waarom?
Eén student volgen door de plaat heen kan soms beter werken dan alle vijf tegelijk in beeld houden. Wat precies het verhaal is, mag je zelf (of je studenten) verzinnen.
Toeschouwers
Twee vrouwen kijken naar de studenten en proberen te snappen wat ze zien. De oudere vrouw pakt er een tablet met AI bij en laat de lastige stof — AI zelf — aan zich uitleggen. De jongere doet het tegenovergestelde: ze maakt met de hand aantekeningen, met een weegschaal die laat zien dat ze de voor- en nadelen afweegt.
Hier draait alles om bewust kiezen wanneer je AI wel of niet inzet. Er is niet één juiste manier: de een leunt op AI om een drempel te verlagen, de ander houdt het denkwerk bij zichzelf. Mooi detail: het cliché wordt omgedraaid — niet de jongere, maar juist de oudere gebruiker omarmt de techniek. Hier bevordert de AI-tool digitale inclusie.

- Wanneer en hoe heeft AI jou geholpen om toegang tot complexe kennis te verlagen?
AI-tools vergroten de kansenongelijkheid tussen arm en rijk / jong en oud / digitaal geletterd en ongeletterd.
AI kan drempels verlagen, maar wie geen toegang, vaardigheden of geld heeft voor de steeds duurdere hulpmiddelen, kan juist achterop raken. Dit heeft impact op de digitale inclusie. "Bewust kiezen" veronderstelt dat je überhaupt kúnt kiezen.
Dataverzameling
Deze scène gaat over het verzamelen van data om AI-systemen te trainen. Het tapijt met "WWW" staat voor het internet als enorme bron, waar bijna alles uit wordt opgezogen: wetenschappelijke teksten, muziek, kunst en allerlei online documenten.
De kern is de afweging tussen eigenaarschap, schaal en zorgvuldigheid. Hoe meer kwalitatief goede data, hoe krachtiger een model lijkt te worden. Maar niet alle data is betrouwbaar, rechtmatig verkregen of geschikt — ook nepnieuws belandt in dezelfde stroom.
En door AI gegenereerde synthetische data kan later opnieuw in datasets terechtkomen, waardoor vervuiling zich opstapelt. Zo wordt duidelijk: de uitkomsten van AI zijn niet neutraal, maar worden gevormd door menselijke keuzes.

- Wat wordt er allemaal opgezogen, en waarom is het riskant dat zulke verschillende soorten informatie in één stroom belanden?
- Als AI leert van wat er tot dat moment online stond, welke informatie of perspectieven blijven dan onderbelicht?
- Wie zou mogen bepalen wat wél en níet in een dataset terechtkomt: bedrijven, wetgevers, makers, onderzoekers, gebruikers of de samenleving?
Synthetische data is nooit geschikt om een nieuw AI-model mee te trainen.
Dataverzameling — drie close-ups

Een muzikant en een schilder zijn aan het werk. Een medewerker met een grote data-stofzuiger zuigt de muzieknoten en de kleuren zónder te vragen op. Hier botst het bouwen van krachtige AI op de auteursrechten van makers: werk belandt in trainingsdata zonder toestemming, bronvermelding of vergoeding — en met diezelfde data maakt AI werk dat met de makers concurreert.
Dataverzameling voor AI-training is geen auteursrechtinbreuk, zolang het systeem later geen exacte kopieën maakt.

De stofzuiger zuigt het hele web op — inclusief een omgevallen prullenbak met nepnieuws ("Aarde is plat", "Aliens gezien") en een door AI gemaakt beeld: dezelfde tutu-deepfake uit scène 13. AI onderscheidt niet vanzelf wat waar, verzonnen of AI-gegenereerd is — garbage in, garbage out. Fouten herhalen zich en zeldzame perspectieven verdwijnen: het risico van model collapse. Méér data betekent niet automatisch betere AI.

Een onderzoeker ziet zijn proefschriften en artikelen de data-stofzuiger in verdwijnen. Wetenschap is aantrekkelijke trainingsdata: betrouwbaar, gecontroleerd en zorgvuldig. Maar waar ligt de grens? Veel onderzoek zit achter een betaalmuur, en tóch belandt het via schaduwbibliotheken, verkochte uitgeverscatalogi en vrije preprints alsnog in trainingsdata.
Voor maatschappelijk waardevolle AI moet individueel eigenaarschap van wetenschappelijk onderzoek soms wijken voor het collectieve belang.
Afspraken over eigenaarschap
De muzikant, de onderzoeker, de kunstenaar en een vertegenwoordiger van een AI-bedrijf zitten samen aan tafel. Ze schudden handen, maken afspraken en bekijken documenten. Achter hen staat een scheidsrechter, die toezicht houdt en de afspraken bewaakt.
Dit is de gewenste situatie tegenover scène 3 (Dataverzameling): vóórdat werk in AI-training belandt, zitten betrokkenen om tafel. De scheidsrechter staat voor regels, toezicht en eerlijke afspraken. AI-training is dus niet alleen een technische kwestie, maar gaat net zo goed over toestemming, auteursrecht, vergoeding, transparantie en publieke waarden.

- Wat is het verschil met de scène met de stofzuiger?
- Welke afspraken zouden op tafel moeten liggen vóór gebruik?
- Wie ontbreekt er misschien nog aan tafel?
- Wie zou de scheidsrechter moeten zijn in deze scène?
Het is altijd beter om AI langzamer te ontwikkelen met duidelijke rechten voor makers, dan sneller met onduidelijke data-afspraken.
De vierde muur doorbreken
Linksonder zit een student gehurkt en tilt een hoek van het beeld op, alsof hij achter de praatplaat kijkt. Op de opgetilde rand staat een tekst die verwijst naar hoe dit materiaal zelf is gemaakt: met generatieve AI.
Dat opgetilde hoekje doorbreekt de normale kijkrichting: niet alleen de inhoud staat ter discussie, maar ook de manier waarop dit materiaal tot stand kwam. Het draait om transparantie over AI in maakprocessen. In het onderwijs gaat het daarbij niet alleen om eerlijkheid, maar ook om voorbeeldgedrag.

- Wanneer moet je vermelden dat AI heeft meegewerkt — altijd, of vooral bij invloed op inhoud, beeld, beoordeling of overtuigingskracht?
- Wat tilt de student op, en wat ontdekt hij daar?
- Wat zou de ontwerper moeten vermelden om transparant te zijn — dát AI is gebruikt, of ook waarvóór?
De ontwerper van deze praatplaat had een echte tekenaar moeten inhuren.
Data opschonen
Op een lopende band schuift een onophoudelijke stroom documenten, afbeeldingen, e-mails en bestanden voorbij. Medewerkers beoordelen wat bruikbaar is: het ene bestand krijgt een vinkje, het andere een rood kruis of waarschuwingsteken. Wat niet door de controle komt, verdwijnt in de afvalbak of wordt weggezogen.
Hier draait alles om de afweging tussen hoeveelheid, kwaliteit en risico. Dubbele bestanden, spam, persoonsgegevens, schadelijke inhoud en ruis zouden zoveel mogelijk uitgefilterd of gemarkeerd moeten worden. De filterinstellingen berusten op keuzes: welke taal telt mee, wat geldt als lage kwaliteit, welke afwijkende stemmen verdwijnen onbedoeld? De grenzen en blinde vlekken van een model ontstaan dus al vóórdat het taalpatronen leert.

- Wat gebeurt er op de band, en welke bestanden worden doorgelaten of tegengehouden?
- Wat kan er misgaan als je te weinig filtert?
- Wat kan er misgaan als je juist te streng filtert?
Een AI-bedrijf mag altijd zelf weten welke data het filtert, zolang het achteraf transparant maakt welke filters zijn gebruikt.
Tokenisatie
Op het scherm wordt de zin "De kat pakt de muis!" in losse stukjes geknipt, en elk stukje krijgt een eigen nummer. De machine ernaast doet hetzelfde met hele documenten: er gaat tekst in, en er komen genummerde eenheden — tokens — uit.
Een model ziet geen woorden of betekenis, maar rekent met getallen. Taal wordt eerst vertaald naar tokens en token-ID’s zodat een computer ermee kan rekenen. Dit proces noemen we tokenisatie. Bij beeldgeneratie werkt dat anders: afbeeldingen worden in kleine rechthoekige blokjes (patches) gedeeld, elk met numerieke codes voor kleur, helderheid en textuur.

- Waarom moeten de woorden eerst omgezet worden in nummers voordat een machine er iets mee kan doen?
- Wat betekent het voor jou dat AI taal niet "leest" zoals jij, maar eigenlijk uitrekent met cijfers?
In dit voorbeeld is elk woord één token, maar in werkelijkheid loopt de grens vaak binnen woorden: lange of zeldzame woorden worden in meerdere stukjes geknipt, veelvoorkomende woorden blijven vaak heel. Tekens zijn vaak aparte tokens.
Pretraining
De getokeniseerde data wordt in grote hoeveelheden in een machine gestort. Binnenin lopen talloze pijlen kriskras tussen de tokens.
In de pretraining leert het model via machine learning zélf taalpatronen herkennen in enorme hoeveelheden data. Het voorspelt steeds welk volgend token waarschijnlijk volgt, en past daarop zijn miljarden parameters aan. Het zoekt geen feiten op en begrijpt taal niet zoals een mens. Keuzes uit eerdere stappen werken door en worden hier in het systeem gebakken. Het resultaat is een ruw taalmodel — het voorspelt taal, maar is nog geen behulpzame of veilige gesprekspartner.
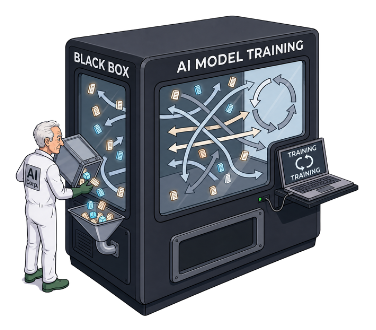
- Wat betekent het dat keuzes uit eerdere stappen hier "in het systeem worden gebakken"?
- Waarin lijkt dit op hoe mensen leren, en waarin niet?
- Waarom staat er "black box" op de machine? Wat zou dit betekenen?
Een AI-model leert niet wezenlijk anders dan een mens: beide leren door patronen te herkennen in voorbeelden.
"Black box" wordt snel te sterk opgevat. De architectuur, het rekenproces en de trainingsmethode zijn juist goed bekend; lastig is vooral hoe aangeleerde patronen tot één specifieke uitkomst leiden.
Interne afstemming & veiligheid
Aan een testopstelling met het bord "Testing — Do no harm" beoordelen medewerkers de uitvoer van een vers model op verschillende schermen: teksten, afbeeldingen en grafieken. Rode waarschuwingsdriehoeken markeren wat misgaat of schadelijk kan zijn.
Een vers getraind model kan taal voorspellen, maar is nog geen betrouwbare assistent. In deze fase wordt het afgestemd op gewenst gedrag: alignment. Interne teams en externe experts proberen het systeem bewust te laten ontsporen. "Do no harm" verwijst naar medische ethiek: voorkom schade. Dat maakt het systeem niet foutloos, maar men probeert grenzen in te bouwen vóór het beschikbaar komt.

- Wat testen de medewerkers, en waarom staan er waarschuwingsdriehoeken bij sommige uitkomsten?
- Wie bepaalt hier wat "gewenst gedrag" is?
Als een AI-systeem ooit slimmer wordt dan de mensheid, dan is alignment onmogelijk.
Alignment en testen verminderen risico’s, maar garanderen geen veilig model. Bovendien is vaak onduidelijk wie verantwoordelijk is als het tóch misgaat: ontwikkelaar, bedrijf, gebruiker of organisatie.
Menselijke feedback & labeling
Op een wereldbol verschijnen laptopschermen waarop mensen de uitvoer van AI beoordelen. Met een duim omhoog of omlaag geven ze aan welke antwoorden beter, behulpzamer, veiliger of ongewenst zijn.
Om een model bij te sturen zijn menselijke oordelen nodig: beoordelaars vergelijken antwoorden, rangschikken uitkomsten of labelen inhoud. AI leert niet uit zichzelf wat gepast of schadelijk is. De globe maakt zichtbaar hoeveel onzichtbare arbeid achter het trainingsproces schuilgaat: vaak uitbesteed, soms onder zware omstandigheden en tegen lage vergoedingen. Deze scène gaat dus ook over arbeid, macht en verantwoordelijkheid.

- Wie geven de duimpjes?
- Waar bevinden zij zich?
- Wat doen ze, denk je?
Er zouden geen mensen gebruikt mogen worden om schadelijke content te labelen.
De duim omhoog/omlaag is een vereenvoudiging. In werkelijkheid vergelijken beoordelaars meerdere antwoorden of voorzien data van gedetailleerde labels. Vooral het filteren van schadelijke inhoud kan mentaal belastend zijn.
Energie- & waterverbruik
Naast de datacentergebouwen staan hoogspanningsmasten en windturbines, en er ligt een waterpartij met koelleidingen. De systemen vragen enorme hoeveelheden stroom, en tegelijk is er veel water nodig om de apparatuur te koelen.
Achter een ogenschijnlijk schoon digitaal antwoord gaat een tastbaar verbruik van energie, water en grondstoffen schuil, met gevolgen voor klimaat en milieu. AI is niet immaterieel: het draait op fysieke infrastructuur in een datacentrum. Het trainen kost in één keer veel energie, maar het dagelijks gebruik door grote aantallen mensen telt daarna nog zwaarder op.

- Woog de opbrengst van jouw laatste AI-interactie op tegen de kosten?
- Wat zouden publieke instanties en overheden kunnen doen om AI(-gebruik) te verduurzamen?
De energie en het water die AI kost, zijn te rechtvaardigen als AI leidt tot belangrijke innovatie in onderwijs, zorg, wetenschap en duurzaamheid.
De milieukosten houden niet op zodra een model klaar is. Over de levensduur ligt het zwaartepunt juist bij het gebruik erna — elke vraag verbruikt opnieuw stroom en water.
AI-bias & regulering
Rondom een arts liggen tientallen vrijwel identieke afbeeldingen: vraag je het systeem om "een arts", dan levert het telkens hetzelfde, eenzijdige beeld. De vraagtekens en de afbeelding die ze omhooghoudt, maken duidelijk dat ze zichzelf daarin niet herkent. Naast haar ligt een boek met "AI ACT" en de Europese sterren.
AI neemt de aannames, stereotyperingen en ongelijkheden uit haar bronnen over en versterkt die — dit noemen we algoritmische bias. Het boek staat voor de Europese AI Act, die zulke risico’s begrenst op basis van risico: hoe groter de mogelijke schade, hoe strenger de eisen. Voor het onderwijs extra relevant: leerprestaties door AI laten beoordelen of studenten plaatsen geldt als hoog risico.

- Waar komt bias vandaan?
- Wie wordt erdoor benadeeld?
- Welke grenzen stelt wetgeving aan AI in gevoelige situaties?
Inclusieve representatie in AI-beelden mag ten koste gaan van historische precisie, zolang het doel is stereotypering te doorbreken.
Bias zit niet alleen in de data, maar sluipt op meerdere momenten binnen — in de dataverzameling (scène 3 — Dataverzameling en scène 6 — Data opschonen), in de labeling en feedback (scène 10 — Menselijke feedback & labeling), in de keuzes van de makers en in hoe het model wordt ingezet.
Deepfakes
Met een beeldgenerator op een laptop heeft iemand een afbeelding gemaakt van een ander in een tutu. Hij houdt het lachend omhoog, terwijl de afgebeelde persoon met over elkaar geslagen armen duidelijk niet meelacht.
Een deepfake maak je met een paar klikken. Vaak lijkt het onschuldig, maar de afgebeelde persoon heeft er niet om gevraagd en kan zich geschaad voelen. En het is niet gratis: een beeld genereren kost veel meer energie en water dan een tekstantwoord. Zulke beelden kunnen leiden tot misleiding, nepnieuws, oplichting en beeld zonder toestemming, en voeden de stroom AI-slop. De AI Act vraagt dat AI-gegenereerde inhoud gemarkeerd wordt.

- Wanneer is iets nog een grap en wanneer wordt het schadelijk?
- In hoeverre is de maker van de AI-tool verantwoordelijk voor de deepfakes die eruit rollen?
- Wanneer moet je vermelden dat iets met AI is gemaakt?
De komst van generatieve AI maakt het internet een onveiligere plek.
Antropomorfisme
Iemand met liefdesverdriet voert als input "dank je wel" in een chatbot, en op het scherm verschijnt de output "You are welcome". In de wolk erboven zie je hoe dat antwoord ontstaat: net als bij tokenisatie kiest het model stap voor stap het meest waarschijnlijke volgende woord. Naast de servers wordt water uit een vijvertje door koelbuizen langs de servers gepompt.
Het beleefde antwoord is geen gevoelde reactie, maar een berekening van wat statistisch het beste past: probabilistische redenatie. Een taalmodel begrijpt, voelt of waardeert niets. Toch schrijven mensen er gemakkelijk menselijke eigenschappen aan toe — antropomorfisme — wat een illusie van vertrouwen en begrip wekt. De pomp en het water tonen dat een vriendelijk bedankje niet gratis is.
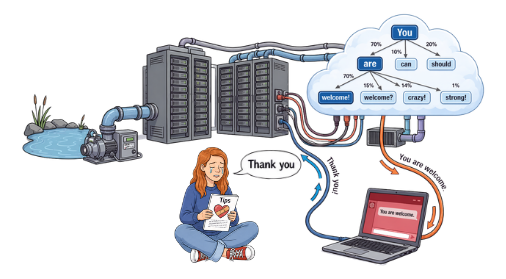
- Wat gebeurt er precies in deze scène?
- Hoe verhoudt de student zich tot de machine?
- Hoe komt de machine tot een antwoord?
- Welke kosten zijn aan dat antwoord verbonden?
We hoeven ons niet beleefd te gedragen tegenover een chatbot.
Beleefd zijn tegen AI is niet "fout" — het zegt iets over jou, niet over de machine. Antropomorfisme is deels bewust ingebouwd: chatbots worden zó ontworpen dat ze menselijk klinken.
Digitale veiligheid
Een inbreker, opgebouwd uit nullen en enen, loert naar de wolk uit de vorige scène: het AI-systeem waaraan mensen van alles toevertrouwen.
Een chatbot voelt als een veilige, persoonlijke ruimte, waardoor gebruikers er soms hun hele levensverhaal in kwijt willen: gezondheidsklachten, geldzorgen, relatieproblemen of gevoelige werkinformatie. Maar die gesprekken kunnen worden opgeslagen bij een bedrijf. Wat als dat bedrijf gehackt wordt en de data op straat komt? Je privégesprekken kunnen in verkeerde handen vallen en gebruikt worden voor oplichting, identiteitsdiefstal of chantage.

- Wat zou jij wél en niet delen met een AI?
- Wat zou de waarde van gelekte privégesprekken kunnen zijn voor hackers?
Je moet nooit je gevoelens delen met een chatbot, want je weet nooit waar deze gesprekken terechtkomen.
Cognitief uitbesteden
Een student ligt ontspannen op de grond een kauwgombel te blazen, terwijl de laptop met het taalmodel (LLM) en de printer het werk doen: er rolt een kant-en-klaar essay uit, hier over de Slag bij Waterloo.
AI kan werk uit handen nemen, maar juist het worstelen met de stof — zoeken, ordenen, formuleren — is wat je iets leert. Wie dat structureel cognitief uitbesteedt, levert sneller een tekst in, maar oefent de denkvaardigheden niet. En in het essay staat 1816, terwijl dat 1815 was: zo’n onjuist "feit" heet een hallucinatie. De student besteedt zo niet alleen denkwerk uit, maar ook zijn oordeelsvermogen. Daarnaast pleegt hij AI-plagiaat.

- Wanneer ondersteunt AI je leren?
- Wanneer ondermijnt AI je leren juist?
Goed kunnen schrijven is minder belangrijk geworden; de nadruk verschuift naar het kritisch beoordelen en bijsturen van AI-teksten.
In werkelijkheid maakt een model deze fout niet snel — 1815 komt zó vaak voor dat het patroon overduidelijk is. Hallucinaties duiken juist op bij zeldzame of slecht gedocumenteerde details, en klinken dan even stellig als correcte informatie.
Experts
Een arts houdt een medisch dossier vast, terwijl een patiënt op een tablet laat zien wat een AI háár heeft verteld — en daarmee de diagnose van de arts in twijfel trekt.
AI maakt informatie heel toegankelijk, maar toegang tot informatie is iets anders dan het kunnen beoordelen ervan. Iemand zonder de juiste kennis en vaardigheden kan een vlot, overtuigend AI-antwoord aanzien voor een betrouwbaar oordeel, en daarbij de afwegingen, context en ervaring van een expert onderschatten.

- Wat gebeurt er tussen de arts en de patiënt?
- Wie lijkt zeker, en waarop is die zekerheid gebaseerd?
- Wat kan een expert wat AI niet of minder goed kan?
Een expert geeft altijd betere adviezen dan AI.
Privacy
Iemand typt gegevens in een chatbot, terwijl op de grond documenten liggen — waaronder een map met "Top Secret". Bedrijfsgeheimen en privacygevoelige stukken gaan zo het systeem in.
Alles wat je invoert, komt bij een extern bedrijf terecht en wordt daar opgeslagen, soms gebruikt om modellen te verbeteren, en is niet zomaar te wissen. Wat handig lijkt — een lastig stuk laten samenvatten — kan betekenen dat vertrouwelijke informatie buiten je organisatie belandt. In stages en op het werk krijg je met vertrouwelijke gegevens te maken, en "even iets in de AI plakken" kan juridische en ethische gevolgen hebben.

- Welke gegevens deel je nooit zomaar met een AI?
Alles wat op het internet staat mag je wel met een chatbot delen, want dat is al openbaar.
Je kunt taalmodellen ook lokaal of op een eigen server draaien, waardoor gegevens niet automatisch bij een externe aanbieder belanden. Dat verkleint het risico, maar maakt het systeem niet vanzelf veilig.
Bewust gebruik
Een weg met een groot "STOP" splitst zich na het stopbord in twee routes: "met AI" en "zonder AI". Er zijn nog meer aftakkingen zichtbaar. Een persoon met een taakkaart staat stil en vraagt zich af wat het doel van de taak is.
Hier staat bewust kiezen centraal: pak je een taak met AI aan, zonder AI, of alleen voor een onderdeel? Niet de techniek staat voorop, maar de vraag wat in deze situatie de beste aanpak is. Soms past een snellere route waarbij AI helpt; op andere momenten is het waardevoller om zelf te denken en te oefenen.
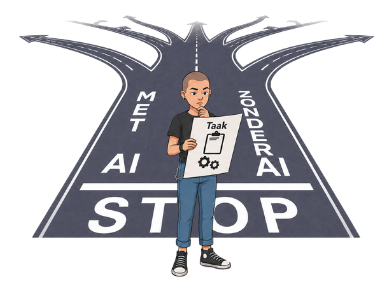
- Voor welke taken maak jij juist heel bewust gebruik van AI?
- In hoeverre sta jij stil bij de impact van AI-gebruik op je leerproces?
- Welke taken doe je bewust zonder AI en waarom?
Beginners leren sneller met AI dan zonder AI, ook als ze nog niet goed kunnen beoordelen of de output klopt.
"Stop" betekent niet dat je AI niet moet gebruiken, maar dat je bewust kiest. Het gaat om een denkpauze: wat wil ik bereiken, waarom, en welk deel doe ik zelf of met AI?
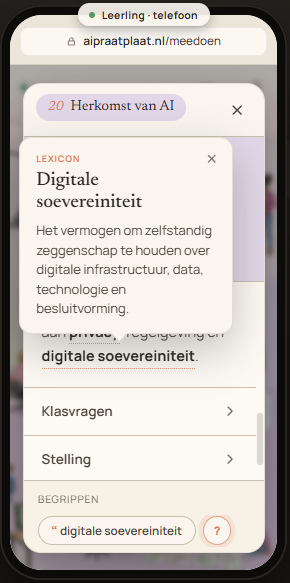
Herkomst van AI
Aan een tafel staan drie laptops, elk gekoppeld aan een vlag uit een ander deel van de wereld (de VS, de EU en China). Mensen vergelijken wat eruit komt, terwijl iemand met een document wijst op de privacyregels die in de eigen regio gelden.
Een AI-model staat nooit los van zijn maker. Achter het systeem zit een bedrijf met een eigen filosofie, rechtssysteem en soms een eigen verhouding tot de overheid.
Dat roept vragen op die verder reiken dan "welk model geeft het beste antwoord?": waar komt jouw data terecht en welke wetgeving geldt daar, hoe denkt de maker over veiligheid en openheid? De keuze voor een model is niet alleen technisch, maar ook ethisch, juridisch en maatschappelijk — en raakt aan privacy, regelgeving en digitale soevereiniteit.

- Welke AI gebruik jij en waarom?
- Welke AI gebruik jij en waar komt deze vandaan?
- Wat zegt de herkomst van een model over wat er met jouw gegevens gebeurt?
We moeten in Europa alleen nog maar Europese AI-systemen gebruiken.
Er is niet één "goed" antwoord. Het krachtigste of populairste model is niet automatisch het meest passende voor jouw taak — een ander model kan beter aansluiten bij jouw eisen rond privacy, regelgeving of waarden.
Tools
Op een gereedschapsbord hangen verschillende AI-tools, elk met een eigen functie: bestanden uploaden, diepgaand onderzoek doen, zoeken, beelden maken, een eigen chatbot bouwen, samen aan een document werken, video genereren, een AI zelfstandig taken laten uitvoeren, en code laten schrijven.
AI is veel meer dan één chatvenster: het is een groeiend gereedschapsbord waaruit je bewust het juiste instrument kiest. Een AI-vaardige gebruiker kan niet alleen technisch met deze tools omgaan, maar is ook informatievaardig — weten welk gereedschap bij welke taak past, en de uitkomst kritisch beoordelen vóór je die overneemt.

- Welke tool gebruik jij zelf het meest — en welke het minst?
- Welke tools voegen het meeste toe aan jouw leerproces?
- Welke tools staan hier niet op?
Dit gereedschapsbord is een momentopname. AI-tools veranderen snel en er komen voortdurend functies bij; ook de benaming kan per applicatie verschillen.
De negen gereedschappen
Het gereedschapsbord uit scène 21 met negen tools.
Upload
Upload een document, presentatie, beeld of code en laat de AI samenvatten of analyseren. Brengt de AI van algemeen naar specifiek — maar je data gaat naar een externe partij en lange stukken worden soms maar deels verwerkt.
Deep Research
Geef een onderzoeksvraag; de AI maakt een plan, raadpleegt veel bronnen en levert een rapport met verwijzingen. Scheelt tijd bij verkennend werk, maar verzonnen bronnen sluipen er ook hier in — controleer ze.
Zoeken
Een AI-samenvatting bovenaan de zoekmachine, of een chatbot die actief het web op gaat. Beide plaatsen AI tussen jou en de bron. Klik door naar de bron in plaats van blind te vertrouwen.
Afbeelding
Genereert illustraties, scènes, schema's of mockups uit een prompt. Indrukwekkend, maar de AI begrijpt niet wát het tekent en kan details verzinnen. Kost veel meer energie en water dan tekst.
Custom Chatbot
Geef vooraf instructies, voorbeelden of bronnen mee, zodat de AI zich gedraagt als schrijfassistent of oefenpartner. Niet “slimmer”, maar gerichter — met dezelfde beperkingen.
Canvas
Je tekst, code of ontwerp staat links open; de AI helpt rechts aan specifieke stukken: herschrijven, inkorten, een argument aanscherpen. Een gedeelde werkruimte om samen iets op te bouwen.
Video
Genereert korte filmpjes uit een prompt, soms met geluid en realistische beweging. Maakt grote indruk en draagt een groter risico: een overtuigende fake-video. De kosten zijn fors — financieel én ecologisch.
Agentmodus
Je geeft de AI een doel in plaats van een vraag. Hij plant stappen, zoekt, gebruikt tools en voert acties uit. Je beoordeelt nu ook het proces — en het risico op foute acties groeit.
Code Generator
Beschrijf in gewone taal wat je wilt bouwen; de AI levert werkende code. Maakt programmeren toegankelijker, maar bevat vaker fouten. Met vibe coding bouw je iets dat je misschien niet kunt repareren.
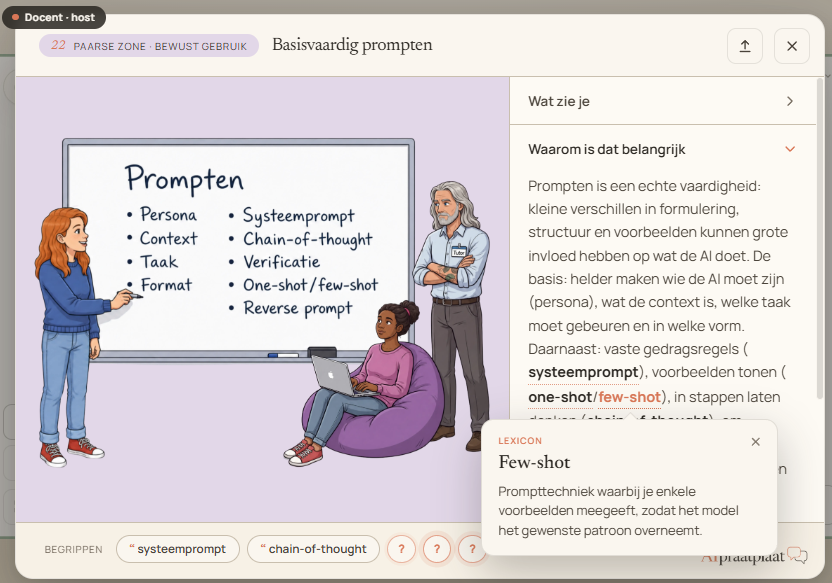
Basisvaardig prompten
Op een whiteboard staan onder de kop "Prompten" verschillende technieken: persona, context, taak, format, systeemprompt, chain-of-thought, verificatie, one-shot/few-shot en reverse prompt. Een student volgt de uitleg over hoe je deze elementen inzet.
Prompten is een echte vaardigheid: kleine verschillen in formulering, structuur en voorbeelden kunnen grote invloed hebben op wat de AI doet. De basis: helder maken wie de AI moet zijn (persona), wat de context is, welke taak moet gebeuren en in welke vorm.
Daarnaast: vaste gedragsregels (systeemprompt), voorbeelden tonen (one-shot/few-shot), in stappen laten denken (chain-of-thought), om controle vragen (verificatie), of via reverse prompting samen achterhalen welke prompt nodig is.

- Welke prompttechnieken gebruiken jullie al?
- Wie gebruikt er wel eens systeemprompts?
- Welke prompttechnieken kun je online nog meer vinden?
Dit terrein verandert snel. Wat vandaag goed werkt, kan bij nieuwere modelversies overbodig zijn — bij de nieuwste modellen hoef je bijvoorbeeld niet altijd een persona mee te geven. Blijf up to date.
Brontriangulatie
Aan een bureau zit dezelfde student die in scène 16 (Cognitief uitbesteden) zijn essay aan AI overliet — nu in een heel andere houding. Hij werkt geconcentreerd: de laptop voor AI-feedback, een tablet met een wetenschappelijk artikel, en daarnaast opengeslagen vakliteratuur.
Een AI-antwoord kan een goed startpunt zijn, maar nooit het eindpunt: je legt het naast minstens een paar andere bronnen om te zien of het klopt en of de nuance overeind blijft. Triangulatie betekent vanuit meerdere kanten naar dezelfde claim kijken, met onafhankelijke bronnen van verschillende soorten. Zo vang je hallucinaties, zwakke AI-samenvattingen en blinde vlekken in trainingsdata op.

- Wat is er veranderd in de houding en aanpak t.o.v. scène 16 (Cognitief uitbesteden)?
- Welke rol speelt elke bron?
- Wat kan AI hier goed?
- Waarom blijft vakliteratuur belangrijk?
Je kunt output van AI nooit vertrouwen; je moet altijd brontriangulatie toepassen.
Creatief denken
Twee mensen staan bij een laptop te overleggen. In de gedachtewolk zien we een iteratief proces waarin studenten en een generatief systeem elkaar afwisselend aanvullen, met zowel divergente als convergente denkbewegingen.
Creatief denken met AI is geen lineair proces van één vraag en één antwoord. Het is een wisselwerking: je geeft richting, de AI doet voorstellen, jij selecteert, scherpt aan, combineert of slaat een andere weg in — waarna de AI verder bouwt. Je vraagt door, laat tegenargumenten formuleren, verkent radicaal andere invalshoeken en gebruikt de AI om je eigen aannames ter discussie te stellen.
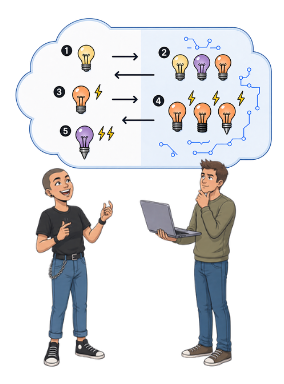
- Welke brainstormtechnieken gebruik jij om met AI nieuwe ideeën op te doen?
- Welke vragen kun je stellen om een AI-antwoord beter, preciezer of bruikbaarder te maken?
- Welke denkstappen moet jij zelf nog zetten nadat AI een eerste voorstel heeft gedaan?
Door AI te gebruiken word je creatiever, omdat je sneller op nieuwe ideeën komt die je alleen niet had kunnen bedenken.
Computationeel denken — een project verdelen
Op een whiteboard is een groter geheel uiteengerafeld in losse taken, van A tot en met G, met pijlen die laten zien hoe ze samenhangen. Bij elke taak staat wie hem het beste kan doen: de mens, de AI, of beide.
Dit is computationeel denken op projectniveau: een complex probleem opdelen, de kern eruit halen en een logische volgorde bepalen. De vraag is niet alleen waar AI kan helpen, maar hoe het hele werkproces wordt ontworpen. AI inzetten bij een grotere opdracht vraagt om management van AI: verdelen, plannen, bewaken en de regie over het eindresultaat houden.
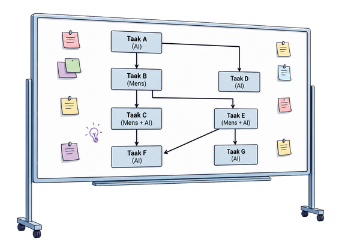
- Welke taken zijn in jouw project geschikt om aan AI te delegeren?
Dit schema oogt netter dan de werkelijkheid. In de praktijk verandert de taakverdeling tijdens het werken. Het doel is niet een perfect schema, maar overzicht, regie en eindverantwoordelijkheid bij de mens houden.
Computationeel denken — de promptketen
Op de grond liggen twaalf prompts, A tot en met L, in een raster. Elke prompt heeft rode of groene markeringen; een student vergelijkt de uitkomsten, herziet en kiest welke aanpak werkt.
Dit is computationeel denken op interactieniveau. Een goed resultaat komt zelden uit één allesomvattende prompt. Je breekt een complexe vraag op in kleinere denkstappen, bepaalt de volgorde, vergelijkt uitkomsten en stuurt bij. De rode en groene markeringen laten zien dat werken met AI ook een vorm van testen en debuggen is.

- Wanneer is een probleem volgens jou "te groot" om in één keer met een prompt op te lossen?
- Met wat voor soort prompts begin jij om een groot probleem aan te pakken met AI?
De scène kan de indruk wekken dat je een promptketen vooraf altijd strak en lineair uitdenkt. In de praktijk is werken met AI creatiever en iteratiever. Deze scène is daarom vooral sterk in combinatie met 24 — creatief denken.
Agentic AI
Aan een dubbel scherm zit een student die een agentic systeem aanstuurt. Een webdesigner kijkt met een notitieblok over zijn schouder mee en peinst over wat dit voor zijn werk betekent.
Agentic AI kan de aard van sommige werkzaamheden drastisch veranderen. Waar een gewone chatbot vooral reageert, kan agentic AI zelfstandig een doel nastreven: stappen plannen, tools gebruiken, informatie ophalen, software aansturen en acties uitvoeren.
De gebruiker ontwerpt, instrueert, monitort en stuurt bij, en bewaakt het contextvenster. Dat vraagt nieuwe vaardigheden: context engineering, veiligheidsbewaking en een werkbare vorm van human-in-the-loop. De verantwoordelijkheid voor het eindresultaat blijft bij de mens.

- Wat is de impact van de AI-agent op de webdesigner die staat toe te kijken?
- Gaat agentic AI ons werk verrijken of vervangen?
- Welke voordelen zie jij bij het gebruiken van agentic AI?
- Welke nadelen zie jij bij het gebruiken van agentic AI?
Agentic AI gaat onze manier van werken verrijken en verbeteren.
De praatplaat online
Alles uit deze handleiding zit ook in de interactieve webversie op aipraatplaat.nl. Je verkent de plaat op een digibord of laptop — sleep om te bewegen, scroll of knijp om te zoomen — en opent scènes als hotspots. Elke hotspot volgt dezelfde opbouw als in deze handleiding:
Hotspots — scènes met een gloeiende contour zijn hotspots: klik erop en de scène opent met uitleg en gespreksmateriaal.
Dezelfde opbouw als dit boekje — Wat zie je, Waarom is dat belangrijk, Klasvragen, Stelling en Let op vind je allemaal terug in een uitklapmenu.
De werkbalk
Onderin het scherm vind je de werkbalk met tools om aan te wijzen, te tekenen en de groep te betrekken. Zweef boven een knop voor een korte uitleg.
Eerst klaarzetten, dan live — alle werkvormen kun je al plaatsen vóórdat de live-modus aanstaat. De live-knop gloeit zacht zodra er gereedschap klaarstaat.
Tekenen blijft van jou — pen-, stift- en laserstrepen verschijnen alleen op het grote scherm; met ongedaan maken of de gum haal je ze weg.
Taal & tekstniveau
De plaat bevat vooralsnog twee talen en drie tekstniveaus.
Rechtsboven schakel je tussen Nederlands en Engels — de interface én alle scèneteksten gaan mee. In de live-modus kiest elke deelnemer op de eigen telefoon zijn eigen taal: zo presenteer jij bijvoorbeeld in het Nederlands, terwijl een internationale student dezelfde scène in het Engels meeleest.
Elke scène bestaat in drie tekstlagen: dezelfde beelden en dezelfde vragen, maar de tekst wordt stap voor stap toegankelijker. In deze betaversie dragen de niveaus nog géén naam — je kiest simpelweg niveau 1, 2 of 3 (in de werkbalk getoond als één, twee of drie bolletjes). Welke laag het best past, bepaal je zelf per groep.
Niveau 3 — de volledige tekst: langere, samengestelde zinnen en vakbegrippen waar ze passen. Niveau 2 — kortere zinnen, minder jargon, begrippen vaker uitgelegd. Niveau 1 — de meest toegankelijke laag: korte, losse zinnen en alledaagse woorden.
Digitale inclusie is de mate waarin mensen toegang, vaardigheden, vertrouwen en ondersteuning hebben om digitaal mee te kunnen doen. Een gesprekstool over AI dat zelf drempels opwerpt — door taal, jargon of leesniveau — zou zijn eigen boodschap ondergraven.
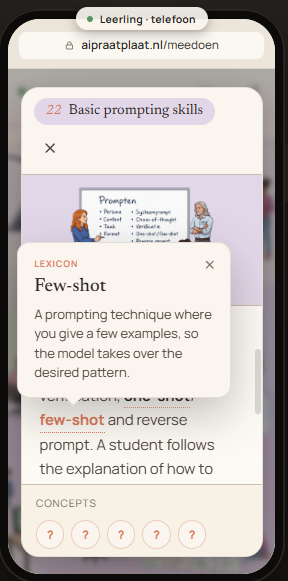
Voorbeeld — scène 1 (De presentatie), „Wat zie je?”
Niveau 3: „Deze centrale afbeelding is de ingang van de praatplaat. Vijf studenten houden samen een praatplaat vast — en in die plaat duiken ze opnieuw op, met weer een praatplaat. Zo ontstaat een droste-effect: een beeld dat zichzelf herhaalt.”
Niveau 2: „Dit is de ingang van de praatplaat. Vijf studenten houden samen een grote plaat vast. Kijk goed: in die plaat staan ze nog een keer, met weer dezelfde plaat in hun handen. Een plaatje in een plaatje in een plaatje — dat blijft zich herhalen. Zoiets heet een droste-effect.”
Niveau 1: „Dit is de ingang van de praatplaat. Vijf studenten houden samen een grote plaat vast. Kijk goed: in die plaat staan ze nog een keer. Met weer dezelfde plaat. Een plaatje in een plaatje in een plaatje. Dat heet een droste-effect.”
Net als op de plaat zelf — scène 2 (Toeschouwers) laat zien hoe AI drempels naar complexe kennis kan verlagen. De praatplaat probeert dat zelf ook te doen: wie meedoet, kiest het niveau en de taal die passen.
Plaatsen, inventaris & pushen
Tools en memo's kun je op twee manieren kwijt. Wat je op een scène plaatst, komt in de inventaris van die scène — en met één knop deel je het met de groep: de push.
Op de plaat pinnen
Kies een tool of memo in de werkbalk en klik op de plek waar die hoort. Plaats je hem op een scène, dan hoort hij automatisch bij die scène.
Vanuit een hotspot
Open een scène en plaats het item rechtstreeks in het venster — zonder los icoon op de plaat.
De inventaris
Alles wat bij een scène hoort — werkvormen, memo's, links en actieve brillen — verzameld in de inventaris van de hotspot.
Bij de deelnemer
Deelnemers vinden dezelfde inventaris terug in de hotspot op hun eigen scherm — als de kijkrechten het toelaten.
Wat jij op de plaat pint, zien deelnemers niet als losse pins op hun scherm — dat zou te veel zicht op de tekening wegnemen. Daarom loopt alles bij hen via de inventaris van de betreffende hotspot en via notificatiebolletjes.
Raak je de tel kwijt? Het itemoverzicht in de werkbalk (onder werkvormen) toont alle werkvormen en gedeelde links op een rij, mét herkomst: gepind op de plaat, in een inventaris, of nog niet geplaatst. Daar kun je ook alle items in één keer vastzetten of verbergen.
Pushen — de belangrijkste knop
Plaatsen is klaarzetten; pushen is delen. Wat je pusht verschijnt direct op elk scherm: een memo in het dock, een werkvorm klapt open, een link staat klaar. Wat je niet pusht, blijft bij jou — en met „niet meer pushen” trek je het ook weer terug. Zodra er een push actief is, zie je hem in de werkbalk staan: één klik opent hem op het grote scherm.
Niets hoeft je op te slaan — klik je een item weg met het kruisje (terug naar de icoontjes), dan blijft het gewoon bestaan. Een werkvorm die je niet op de plaat hebt gepind én niet in een inventaris hebt gezet — bijvoorbeeld een losse woordwolk — vind je altijd terug via Werkvormen → Mijn items, rechtsonder in het uitklapmenu (de drie streepjes).
Live-modus — jij houdt de regie
Start een live-sessie en iedereen kijkt mee op het eigen scherm. Wat jij pusht, verschijnt direct bij de deelnemers. Deelnemers doen anoniem mee en sessiegegevens worden alleen tijdens de sessie bewaard — daarna worden ze direct verwijderd.
Start de live-modus
Klik op de live-knop in de werkbalk en open de sessie. Je krijgt een sessiecode en een link om te delen.
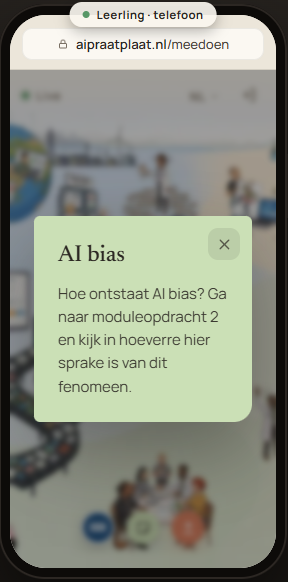
Deel de code
Deelnemers gaan naar aipraatplaat.nl/meedoen en vullen de code in. Het systeem wijst anonieme badges toe, zoals „Nieuwsgierige Variabele”.
Wacht op de groep
Je ziet het aantal deelnemers in de wachtruimte oplopen. Start de sessie en iedereen krijgt de plaat in beeld.
Push wat je wilt delen
Memo's, werkvormen, zoekopdrachten en stellingen verschijnen meteen op elk scherm — en verdwijnen zodra jij ze terugtrekt.
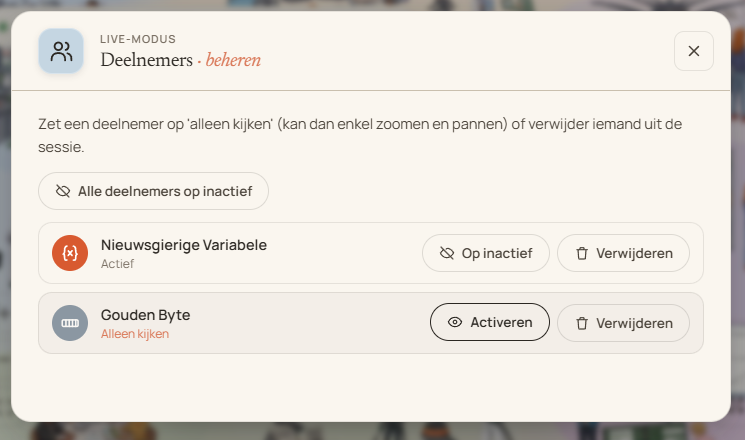
Zet een deelnemer — of in één keer de hele groep — op „alleen kijken”: diegene kan dan enkel zoomen en pannen. Verwijderen kan ook; opnieuw meedoen kan altijd met de sessiecode (tenzij je deze op slot hebt gezet).
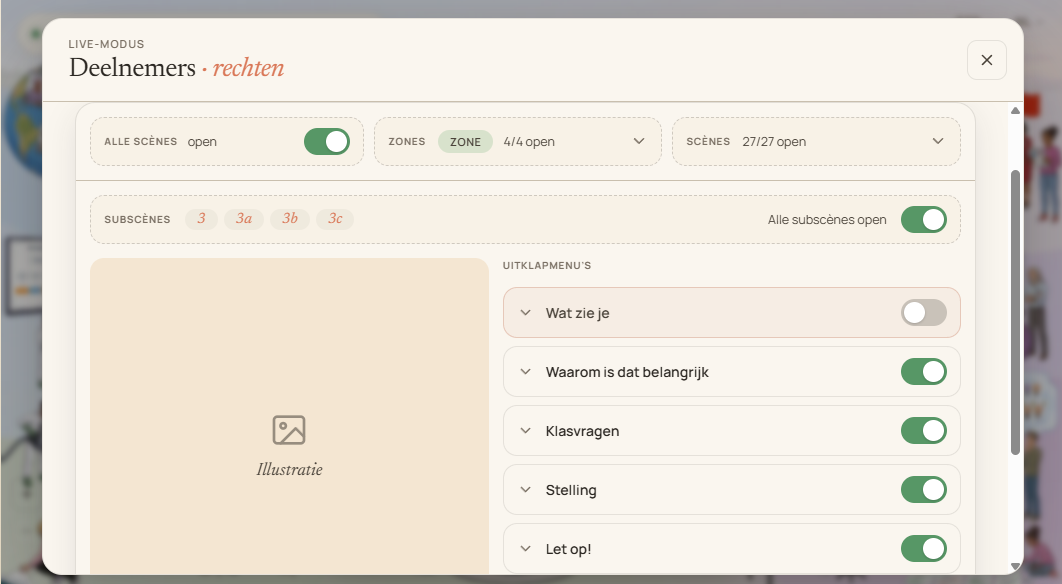
Bepaal precies wat deelnemers op hun eigen plaat mogen openen: per zone, per scène, per subscène en zelfs per uitklapmenu. Geef bijvoorbeeld wél de illustratie en de klasvragen vrij, maar houd de stelling nog even achter de hand.
Memo's, links & zoekopdrachten
Met drie tools kun je aandacht sturen: de memo — een digitaal plakbriefje op de plaat — de link, waarmee je een artikel of video bij de groep brengt, en de zoekopdracht: een speurvraag waarmee de groep zelf de plaat onderzoekt.
Plak een memo op de plaat met een vraag, opdracht of aandachtspunt, en push hem naar alle schermen. Deelnemers vinden gepushte memo's terug in het dock onderin hun scherm, dus ook wie later kijkt mist niets.
Deel een link via het werkvormen-menu: prik hem als chip op de plaat of push direct naar de deelnemers.
Typ een eigen opdracht, laat de dobbelsteen een willekeurige kiezen, of pak een begrip — „Waar op de praatplaat zie je iets over tokenisatie?". Koppel er optioneel een memo of een link aan, en bepaal of de hotspots tijdens de opdracht aan of uit staan. Kies ook wat deelnemers insturen: niets, een pin op hun eigen plaat, of een pin met een korte notitie. Een timer erbij kan ook.
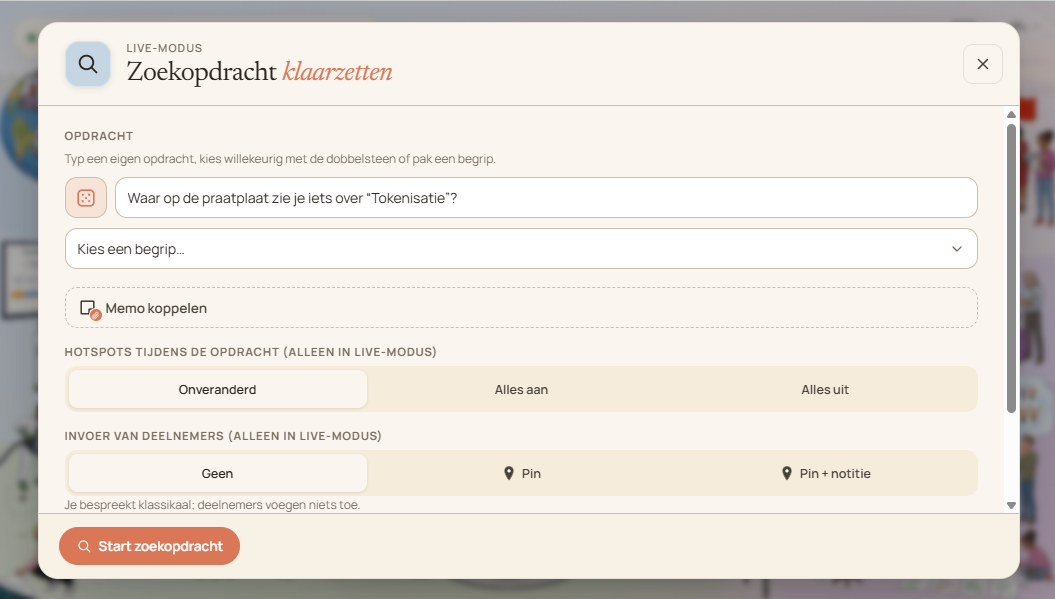
Dobbelsteen, begrip of eigen vraag — en start.

Elke deelnemer sleept een pin — eventueel met notitie — naar de plek op de eigen plaat.
Tijdens de opdracht verschijnen de pins op jouw plaat.
Clusters van pins laten in één oogopslag zien hoe de groep de vraag leest.
Woordwolk, poll & kort antwoord
Drie interactieve werkvormen halen live input op: de woordwolk (open associaties), de poll (gesloten vraag met live uitslag) en het korte antwoord (een zin of twee, leesbaar voor de hele groep). Je plaatst ze bij een scène, pusht ze naar de telefoons en toont het resultaat op het grote scherm — terwijl de antwoorden binnenstromen.
Kies de werkvorm in de werkbalk en klik op de plek op de plaat waar de vraag bij hoort. Bewerk de vraag — en bij een poll de antwoorden, minimaal twee en maximaal acht — en push. Op elke telefoon klapt direct het antwoordvenster open.
Open de werkvorm op het grote scherm en de resultaten groeien live mee. Vergrendel de inzendingen zodra je wilt bespreken, wis alles voor een tweede ronde, of haal de vraag van de schermen met „niet meer pushen".
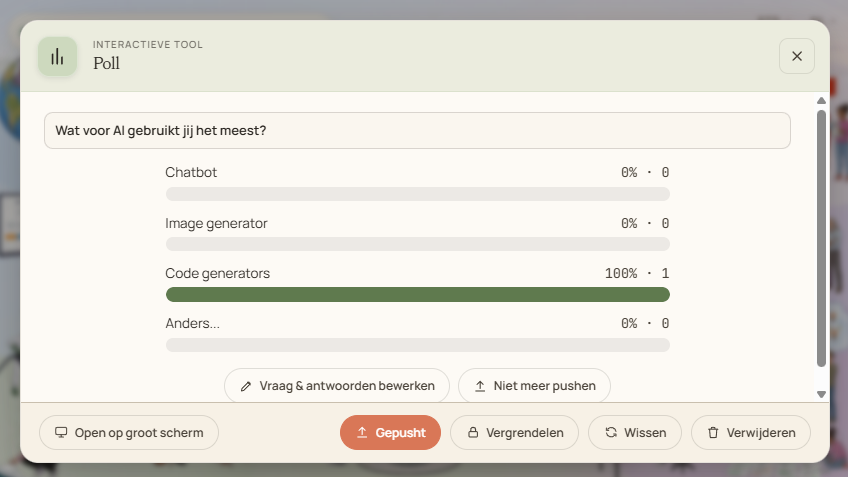
Resultaten groeien live mee; onderin push, vergrendel of wis je de inzendingen.
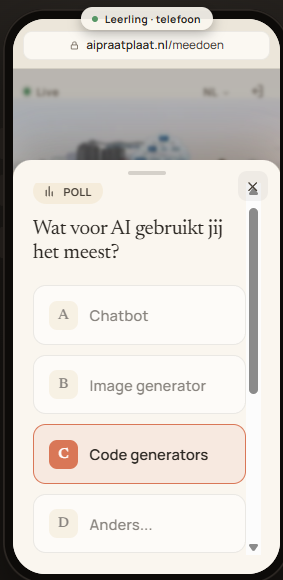
Wat jij pusht, klapt bij de deelnemer open; insturen kan tot jij vergrendelt.
Perspectiefbrillen
Geef elke deelnemer een bril: een perspectief van waaruit die naar de plaat kijkt. Het systeem verdeelt de brillen willekeurig en elke deelnemer ziet alleen de eigen bril.
Belanghebbenden
Maker · Gebruiker · Ontwikkelaar · Toezichthouder · Samenleving
Maatschappelijke brillen
Cultureel · Sociaal · Ecologisch · Politiek · Economisch · Juridisch
Debatbrillen
Voorstander · Tegenstander · Twijfelaar · Bemiddelaar · Overdrijver
Waardenbrillen
Gelijkheid · Eerlijkheid · Rechtvaardigheid · Openheid · Veiligheid
Individuele brillen BEPERKT UITDELEN
Gespreksleider · Notulist · Mol · Hacker · Doemdenker · Autocraat
Elke bril kan een eigen begeleidende kijkvraag meekrijgen. Deze kan aangepast worden.
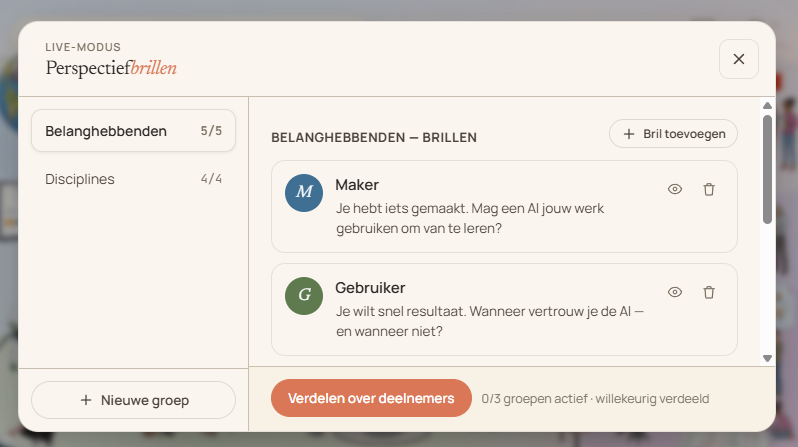
Klik op de naam of de kijkvraag van een bril om de tekst te bewerken. Brillen kun je toevoegen, tijdelijk uitschakelen of verwijderen — en met „Nieuwe groep” maak je een set voor jouw vak of casus.
Brillen kunnen ook beperkt uitgedeeld worden. De groep met individuele brillen is daar een voorbeeld van. Zo breng je ongemerkt één mol, twee hackers of één gespreksleider in.
Deelnemers zien niet welke bril een ander heeft.
Didactische handvatten
De praatplaat biedt veel mogelijkheden om werkvormen te combineren. Om je op weg te helpen zijn hier zes ideeën om uit te proberen.
Eerst de bril, dan de stelling
Verdeel de perspectiefbrillen vóórdat je de stelling pusht: het perspectief kleurt direct de waarneming. Laat iedereen vanuit de eigen bril reageren en zet de botsende perspectieven daarna tegenover elkaar . Daarna is het natuurlijk leuk om de brillen opnieuw te verdelen.
Van nieuwsbericht naar plaat
Neem een actuele casus mee — een deepfake-rel, een rechtszaak over trainingsdata — en zet een zoekopdracht in met gekoppelde link: „Waar heeft dit nieuwsbericht het meeste raakvlak mee op deze praatplaat?” Kies pin + notitie en bespreek de clusters: waarom prikt de helft bij scène 13 en een enkeling bij scène 3?
Voor- en nameting
Push de stelling als poll (eens / oneens / twijfel) vóórdat er iemand iets gezegd heeft — anoniem stemmen maakt ook de stille meningen zichtbaar. Vergrendel de uitslag, voer de discussie, wis en stem eventueel opnieuw.
Breng een mol in het gesprek
Deel uit de groep „Individuele brillen” één of enkele rollen uit: een gespreksleider die beurten geeft, een notulist — of geheim: een mol die het gesprek subtiel saboteert. Niemand weet wie welke rol kreeg. Zo geef je studenten meer invloed op het verloop van het gesprek.
Stille denkronde
Zet de hotspots uit en kies bij de zoekopdracht „pin + notitie”: eerst kijkt en prikt iedereen zelf (denken), daarna vergelijk je klassikaal (delen). Zonder hotspots moet de groep écht naar de tekening kijken in plaats van alles in de hotspots te lezen.
Laat de dobbelsteen kiezen
Geen idee waar je moet beginnen? Laat de dobbelsteen in het zoekopdracht-venster een willekeurige opdracht kiezen en ga samen met je doelgroep op zoek. Jij weet het antwoord ook niet van tevoren — een gezamenlijke ontdekkingstocht dus!
Een complete sessie in zes zetten
Je kunt ook werkvormen in een schakel combineren tot een complete les.
Woordwolk als nulmeting Woordwolk
„Waar denk je aan bij digitale inclusiveit?” — de eerste wolk toont wat er leeft, zonder dat één stem domineert. Je activeert de voorkennis,
Eén scène open, de rest dicht Kijkrechten
Kies de scène die bij je les past en geef alleen die vrij: gedeelde aandacht, geen afdwalende telefoons.
Klasvragen bespreken Hotspot
Begin met „Wat zie je?” en voeg pas daarna context toe. De klasvragen in de hotspot helpen je op weg.
Brillen verdelen Perspectiefbrillen
Eén klik verdeelt de perspectieven. Laat de groep de scène opnieuw bekijken — nu door een andere bril.
Stelling als poll Poll×Stelling
Anoniem stemmen, discussie vanuit de brillen, opnieuw stemmen: de verschuiving is de opbrengst.
Kort antwoord als exit-ticket Kort antwoord
„Wat zou jij anders doen?” of „Welk begrip snap je nog niet?” — directe input voor je volgende les.
Maak het je eigen — de didactische handvatten in deze handleiding zijn slechts een startpunt. Als docent kun je eindeloos variëren met deze tools: de regie en het initiatief ligt nu bij jou.
Pedagogische memo’s
De technische knoppen en de didactische recepten dienen natuurlijk een doel: het gesprek tussen jou en je doelgroep op gang brengen, om wederzijds begrip te kweken, en om samen te leren over deze bijzondere, impactvolle systeemtechnologie. Hier zijn nog zes handige memo’s om in het achterhoofd te houden voordat je begint.
Je hoeft niet alles over AI te weten
Docentontwikkeling rond AI is een proces van levenslang professioneel leren, met nadruk op teacher agency en een mensgerichte mindset: AI dient de menselijke ontwikkeling — niet andersom. Het gesprek kan dus al beginnen vóórdat jij alle antwoorden hebt.
Veilige klas eerst
AI-schaamte is reëel — zie scène 1. Boos worden op je doelgroep omdat ze AI gebruiken heeft geen zin: dan raak je ze kwijt. Wie zonder oordeel kan vertellen wat die met AI doet, kan er ook kritisch op leren reflecteren.
Ethiek zit in elke scène
Net als in het AI-GO raamwerk is ethiek hier niet één component naast kennis, vaardigheden en attituden, maar het fundament waarop die drie rusten. Ethiek speelt daarom altijd een rol: Wie betaalt? Wie beslist? Wie wordt geraakt? Wat vinden wij hiervan?
Praten draagt bij aan AI-geletterdheid
AI bespreken met je doelgroep is didactische competentie die al bijdraagt aan de ontwikkeling van AI-geletterdheid. Het klassengesprek is dus geen opmaat naar de „echte” leerstof — het is de leerstof.
Twee geletterdheden tegelijk
AI loopt transversaal door alle 21 competenties van DigComp 3.0, en het AI-kerndoel raakt elk domein van digitale geletterdheid. Elk scènegesprek over deepfakes, data of privacy is ook een les in bijvoorbeeld informatievaardigheden, mediawijsheid en/of digitale veiligheid.
Van elkaar leren
Jouw doelgroep brengt gebruikservaring mee die jij misschien niet hebt; jij brengt duiding, context en ethische scherpte. De plaat is de gedeelde plek waar die twee elkaar ontmoeten. Het gaat er niet om wie er gelijk heeft, maar om te duiden wat we zien en wat het voor ons betekent en hoe we hier wat van elkaar kunnen leren.
Lexicon
Het cijfer verwijst naar de scène(s) waar het begrip vooral speelt.
- agentic AI 27
- AI-systemen die niet alleen reageren op losse prompts, maar zelf tussenstappen plannen, tools gebruiken en acties uitvoeren om een doel te bereiken.
- AI Act 12, 13
- Europese wetgeving die AI-systemen risicogebaseerd reguleert en organisaties verplicht verantwoord met AI om te gaan.
- AI-geletterdheid
- Het samenspel van kennis, vaardigheden en attituden, waarbij ethisch bewustzijn de basis vormt voor het kritisch, verantwoordelijk en effectief omgaan met AI-systemen.
- AI-plagiaat 16
- Het overnemen of inleveren van AI-gegenereerde inhoud zonder transparantie over de herkomst of de eigen bijdrage.
- AI-schaamte 1
- Het ongemakkelijke gevoel dat kan ontstaan wanneer iemand AI gebruikt, zeker als onduidelijk is of dat als eerlijk of professioneel wordt gezien.
- AI-slop 13
- Grote hoeveelheden laagwaardige AI-gegenereerde inhoud die informatieomgevingen kunnen vervuilen.
- algoritmische bias 12
- De systematische vertekening waarbij een AI-systeem aannames, stereotyperingen en ongelijkheden uit zijn bronnen overneemt en versterkt.
- alignment 9, 10
- Het afstemmen van een AI-model op gewenst gedrag, bijvoorbeeld zodat het behulpzamer, veiliger en minder schadelijk reageert.
- antropomorfisme 14
- Het toeschrijven van menselijke eigenschappen, gevoelens of intenties aan iets dat niet menselijk is.
- auteursrecht 3a, 4
- Het recht van een maker om te bepalen hoe zijn of haar werk gebruikt, gekopieerd of verspreid wordt.
- black box 8
- Een AI-systeem waarvan de interne werking niet of nauwelijks inzichtelijk is voor gebruikers of ontwikkelaars.
- brontriangulatie 23
- Het controleren van een claim door meerdere onafhankelijke bronnen en perspectieven naast elkaar te leggen.
- chain-of-thought 22
- Prompttechniek waarbij je het model vraagt zijn redenering stap voor stap uit te schrijven, voor een beter onderbouwd antwoord.
- cognitieve uitbesteding 16
- Het delegeren van mentale taken, zoals onthouden, analyseren of schrijven, aan externe hulpmiddelen.
- computationeel denken 25, 26
- Een manier van denken waarbij je problemen opdeelt, patronen herkent, stappen ordent en oplossingen systematisch ontwerpt.
- context engineering 27
- Het dynamisch selecteren, structureren en optimaliseren van de informatie in het contextvenster van een AI-model.
- contextvenster 27
- De hoeveelheid tokens in de input en output die een model op een gegeven moment kan verwerken en onthouden.
- datacentrum 11
- Fysieke infrastructuur met servers, koeling, energievoorziening en netwerkverbindingen waarop AI-systemen draaien.
- debuggen 26
- Het opsporen, begrijpen en verbeteren van fouten in code, prompts, redeneringen of werkprocessen.
- deepfake 3b, 13
- AI-gegenereerde of bewerkte media waarin een persoon iets lijkt te doen of zeggen wat diegene niet echt deed of zei.
- digitale inclusie 2
- De mate waarin mensen toegang, vaardigheden, vertrouwen en ondersteuning hebben om digitaal mee te kunnen doen.
- digitale soevereiniteit 20
- Het vermogen om zelfstandig zeggenschap te houden over digitale infrastructuur, data, technologie en besluitvorming.
- digitale veiligheid 15, 18
- Het beschermen van gegevens, systemen en gebruikers tegen ongewenste toegang, misbruik, verlies of schade.
- do no harm 9
- Ethisch uitgangspunt dat een AI-systeem zo ontworpen en gebruikt wordt dat het geen schade veroorzaakt.
- few-shot 22
- Prompttechniek waarbij je enkele voorbeelden meegeeft, zodat het model het gewenste patroon overneemt.
- garbage in, garbage out 3b
- Het principe dat slechte, vervuilde of misleidende input kan leiden tot slechte, vervuilde of misleidende output.
- generatieve AI 5
- Computertechnieken die op basis van trainingsgegevens schijnbaar nieuwe, "betekenisvolle" inhoud genereren, zoals tekst, afbeeldingen of audio.
- hallucinatie 16, 23
- Feitelijk onjuiste AI-uitvoer die wél overtuigend en stellig kan klinken.
Lexicon (vervolg)
- human-in-the-loop 10, 27
- Een werkwijze waarbij een mens toezicht houdt, bijstuurt of eindverantwoordelijkheid neemt in een AI-proces.
- input 14
- Alles wat een gebruiker of systeem aan AI meegeeft, zoals tekst, data, afbeeldingen, instructies of documenten.
- labelen 10
- Het voorzien van data of modeluitvoer van labels, beoordelingen of voorkeuren, vaak als onderdeel van training.
- LLM 16
- Large Language Model: een groot taalmodel dat getraind is op enorme hoeveelheden tekst en op basis van waarschijnlijkheid het volgende token voorspelt.
- machine learning 8
- Een benadering waarbij systemen patronen leren uit data in plaats van alleen vooraf geprogrammeerde regels te volgen.
- menselijke regie 2, 17, 19, 25
- Het vermogen en de verantwoordelijkheid van mensen om AI bewust aan te sturen, te begrenzen en te beoordelen.
- model collapse 3, 3b
- Het risico dat modellen slechter of eenvormiger worden wanneer ze steeds op AI-gegenereerde of vervuilde data trainen.
- one-shot 22
- Prompttechniek waarbij je één voorbeeld meegeeft, zodat het model het gewenste patroon overneemt.
- output 14
- Het resultaat dat een AI-systeem teruggeeft, zoals tekst, beeld of code.
- parameters 8
- Interne instellingen van een model die tijdens training worden aangepast en mede bepalen welke output waarschijnlijk wordt.
- pretraining 8
- De vroege trainingsfase waarin een model op grote hoeveelheden data leert patronen te voorspellen.
- privacy 15, 18, 20
- Het zorgvuldig omgaan met persoonsgegevens, vertrouwelijke informatie en datadeling.
- probabilistisch redeneren 14
- Werken met waarschijnlijkheden: het systeem kiest wat statistisch het meest passend is, niet wat het echt begrijpt.
- reverse prompting 22
- Een techniek waarbij je vanuit een gewenste uitkomst terugredeneert naar een betere prompt of instructie.
- synthetische data 3
- Kunstmatig gegenereerde data.
- systeemprompt 22
- Een vooraf ingestelde instructie die het gedrag, de rol of de grenzen van een AI-systeem stuurt.
- token 7
- Een stukje tekst dat een model als rekeneenheid verwerkt: een woord, deel van een woord of teken.
- tokenisatie 7
- Het opknippen van taal in tokens en token-ID’s, zodat een computer ermee kan rekenen.
- transparantie 1, 4, 5
- Openheid over hoe en wanneer AI is gebruikt, welke bronnen of data eraan ten grondslag liggen en hoe een uitkomst tot stand kwam.
- triangulatie
- Een claim vanuit meerdere kanten controleren door onafhankelijke bronnen van verschillende soorten naast elkaar te leggen.
- vibe coding 21i
- Softwareontwikkeling waarbij je sterk leunt op AI om code te schrijven, aan te passen en te beheren.
Cosgrove, J., & Cachia, R. (2025). DigComp 3.0: European Digital Competence Framework — Fifth Edition. Publications Office of the European Union.
Cukurova, M., & Miao, F. (2024). AI competency framework for teachers. UNESCO Publishing.
European Commission. (2025). Empowering Learners for the Age of AI: An AI Literacy Framework for Primary and Secondary Education.
Last, B., Naberink, T., & Mutsaarts, M. (2026). AI-geletterdheid voor docenten.
Miao, F., & Shiohira, K. (2024). AI competency framework for students. UNESCO Publishing.
Renkema, M., Van den Boom-Muilenburg, E., Friso-van den Bos, I., Theelen, H., Wopereis, I., & Schildkamp, K. (2025). AI-GO! Een Raamwerk voor AI-Geletterdheid in het Onderwijs. Utrecht: Npuls AI- en Datageletterdheid.
SLO (2025). Definitieve conceptkerndoelen digitale geletterdheid. SLO, in opdracht van het ministerie van OCW.
Wetenschappelijke Raad voor het Regeringsbeleid (2021). Opgave AI. De nieuwe systeemtechnologie. WRR-Rapport 105.